
1. 왜 2026년 비즈니스의 핵심은 '문서 비식별화'일까요?

기업 데이터의 상당 부분은 PDF, Word, HWP와 같은 문서 형태로 존재합니다.
이 안에는 정형화되지 않은 이름, 주소, 주민번호가 혼재되어 있어 수작업으로는 완벽한 보안이 불가능합니다.
⠀
🛠️문서 비식별화의 3가지 핵심 기술적 요건

① 포맷 호환성 - PDF, HWP, DOCX 등 다양한 문서 규격을 정확히 파싱해야 합니다.
② 레이아웃 보존 - 비식별 처리 후에도 문서의 표, 그림, 글꼴 등 원래 형태가 유지되어야 합니다.
③ 대량 처리 - 수만 권의 전자 문서를 실시간으로 스캔하여 마스킹할 수 있어야 합니다.
⠀
⠀
2. 자연어 처리(NLP)는 어떻게 문서 속 맥락을 읽어낼까요?
최신 NLP(자연어 처리) 기술은 단순 단어 검색을 넘어 문장의 의미를 분석해 개인정보를 탐지합니다.
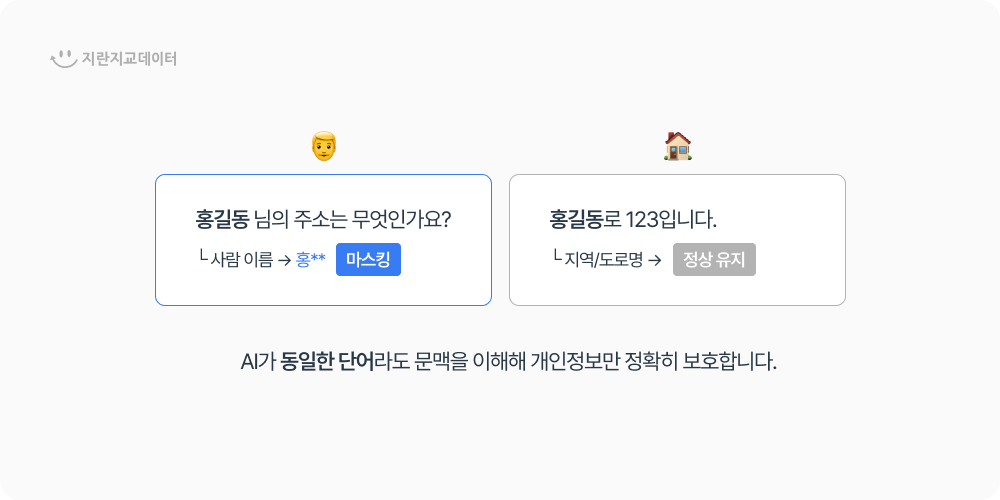
• 문맥 기반 탐지 : <수신인 - 홍길동>과 <동네 이름 - 홍길동>을 구분하여 실제 이름만 정확히 가립니다.
• 다양한 서술형 대응 : 상담 로그나 진술서처럼 자유로운 서술형 문장에서도 개인정보 패턴을 99% 이상 추출합니다.
⠀
⠀
3. 이미지와 문서 내 표(Table) 속 정보는 어떻게 가릴까요?
문서 안에 포함된 이미지나 복잡한 표 속 정보는 OCR(광학 문자 인식) 기술을 통해 처리합니다.
⠀
👀 이미지/문서 자동 추출 및 마스킹 프로세스

① 영역 추출 - 문서 내 이미지나 표의 위치를 AI가 식별합니다.
② 텍스트 추출 - OCR 엔진이 해당 영역의 텍스트와 좌표 정보를 읽어들입니다.
③ 좌표 마스킹 - 개인정보가 위치한 정확한 좌표값에만 마스킹을 적용해 원본을 유지합니다.
⠀
⠀
3. [도입 사례] 공공·금융권의 문서 비식별화 성공 전략
실제 현장에서는 데이터 활용의 속도와 보안성이 비약적으로 향상되었습니다.
⠀
🏢 산업군별 비정형 데이터 비식별화 사례

업종별 특화된 데이터 환경에서도 AI는 정교한 비식별 처리를 수행합니다.
단순히 정보를 가리는 것을 넘어, 데이터의 연구 및 마케팅 활용 가치를 극대화하는 것이 핵심입니다.
⠀
⠀
4. 수작업 대비 AI 자동화 솔루션의 효율성은 얼마나 차이 날까요?
비식별화 자동화는 단순한 보안을 넘어 경영 효율화(BPR/RPA)의 핵심 동력입니다.
⠀
🤖 수작업 vs AI 자동화 비식별 처리 비교

수작업의 한계를 극복한 AI 자동화는 비용 절감뿐만 아니라 인적 오류로 인한 보안 사고를 원천 차단합니다.
반복적인 업무는 AI에 맡기고, 인력은 더 가치 있는 데이터 분석에 집중할 수 있습니다.
⠀
⠀
⁉️ 자주 묻는 질문 (FAQ)
Q1. PDF나 HWP 문서의 디자인이 깨지지는 않나요?
→ 아닙니다. 문서의 레이아웃과 폰트 정보를 유지하면서 텍스트 영역만 마스킹하거나 가명 정보로 치환하므로 원본 가독성이 보존됩니다.
Q2. 스캔된 이미지 문서도 처리가 가능한가요?
→ 네, 고성능 OCR 엔진을 통해 기울어지거나 저화질인 이미지 문서 내 텍스트까지 완벽하게 추출하여 비식별 처리할 수 있습니다.
Q3. 기존 RPA 시스템과 연동이 가능한가요?
→ 표준 API 방식을 지원하여 기존의 RPA, 그룹웨어, 고객 관리 시스템(CRM)과 손쉽게 연동하여 자동 업무 프로세스를 구축할 수 있습니다.
⠀
⠀
⠀
🏆 OCR부터 비식별까지, 환경에 맞춰 AI로 더 똑똑하게!
보안은 기술을 넘어, 데이터의 가치를 완성하는 마지막 퍼즐입니다.
지란지교데이터의 AI필터는 엑셀부터 PDF, HWP 문서, 상담 로그, 이미지까지 기업이 가진 모든 데이터를 안전하게 보호합니다.
지금 바로 OCR 개인정보 관리 솔루션 AI필터를 만나보세요 ✔️

⠀
#비정형데이터 #비식별화 #개인정보보호 #데이터보안 #AI보안 #문서비식별
#NLP #OCR #데이터마스킹 #가명정보처리 #2026IT트렌드 #지란지교데이터



